מדריך לבניית API דרך AWS 🌥️

הצגת מזג האוויר, קבלת המחיר בנתיב המהיר והרצת בינה מלאכותית; מה שמשותף לכולם היא צורת התקשרות - API. באמצעות API למפתחים היכולת לתקשר בין אפליקציות ותוכנות שונות, ומאפשרות להעצים את יכולות המוצר דרך כך. במדריך זה נבנה יחד בצורה מדורגת API לשמירת פרטי חפצים. אסביר לעומק את שירותי AWS, את הפונקציות שנבנה ואיך נחבר הכל יחד בצורה מאובטחת.
רקע 🤔 #
בשנים האחרונות ארכיטקטורת האתרים עוברת שינוי תפיסה. חברות הענק הבינו ששיטת השרתים On-premise לא עובדת, וניסו למצוא פתרון. הפתרון שמצאו הוא לקחת על עצמם לנהל מקצה לקצה את הענן, ולתת למפתחים חווית Serverless. מה Serverless פותר?
- תשלום על שימוש בלבד - תשלום בזמן אמת בהתאם לשימוש המשאבים בפועל, בצורה דינאמית וברזולוציית millisecond.
- ללא תחזוקה - חברת הענן אחראית על ניהול החומרה ותוכנה, ובכך מורידה עומס ועבודה מחזורית של אנשי DevOps בחברה.
- משאבים - הקצאת המשאבים משתנה בהתאם לצורך, ובכך הלקוחות מוכנים לירידה בצורך בהתאמה גם לעלייה בדרישה למשאבים.
- זמינות - לחברות הענן קיימים שרתים ברחבי העולם, להם פרוטוקול תפעול מוסדר שמבטיח זמינות מלאה, גם במקרי קיצון.
- סיבוכיות - מאפשר למפתחים להתרכז במוצר מאשר בתחזוקה שגרתית של תשתיות וארכיטקטורה.
ישנם אתגרים המלווים במעבר ל-Serverless וגישה זו לא מתאימה לכלל המוצרים והחברות, להרחבה בנושא.
שרת הענן הגדול בעולם הינו AWS, אחריו Azure ולאחר מכן GCP. לכל שירות יש יתרונות וחסרונות. אישית, אני לא מעט זמן לומד על AWS, ובפוסט זה החלטתי להתמקד בהם. על מנת לעקוב יחד איתי, הירשמו ל-Console של AWS.
המשימה 🎯 #
המשימה שלנו היא לבנות מערכת עצמאית שתוכל לנהל מסד נתונים על מוצרים, בצורה מאובטחת ויעילה. כתבתי את המדריך עם כמה שיותר הסברים, תמונות והמחשות וויזואליות, בשביל לעזור במידה ואתם נחפשים בפעם הראשונה ל-AWS.
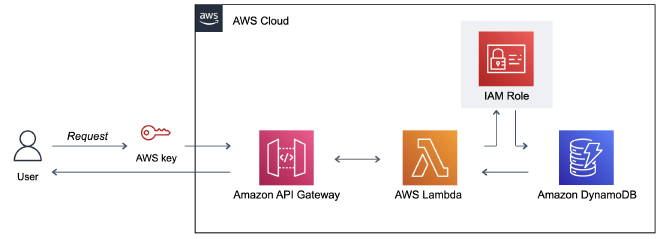
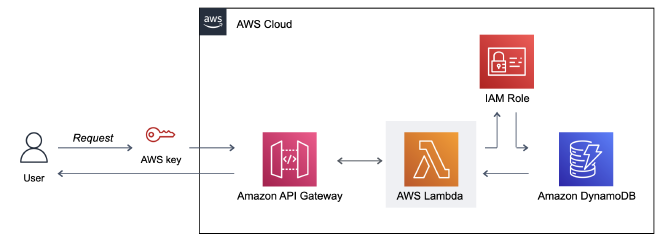
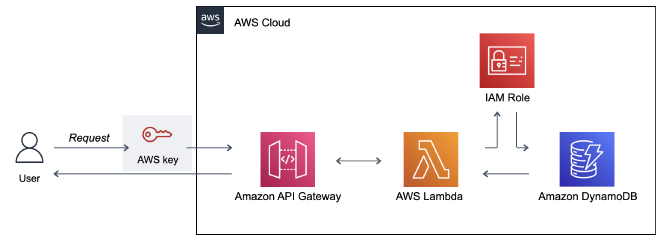
איך? נבנה Private API באמצעות API Gateway. נשתמש ב-Lambda Functions על מנת לבצע את פעולות ה-CRUD על גבי טבלת DynamoDB. בשביל לאפשר את החיבור בין הפונקציה למסד הנתונים נגדיר IAM Role. הכנתי דיאגרמה שתלווה אותנו לאורך המדריך.
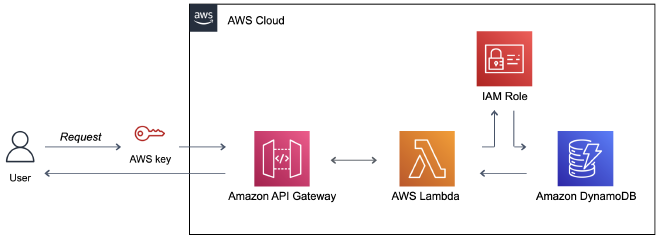
סינית? בואו נלמד יחד!
מסד הנתונים ☁️ #
נרצה לרכז בטבלה פרטים על מוצרים שונים. לכל מוצר יהיה רשומה (record), עם Unique ID. חלק מייתרונות NoSQL היא העובדה שהמבנה בין כל רשומה ורשומה יכולים להשתנות, ומה שנשאר קבוע הוא ה-ID.
אני ממליץ להסתכל על הסרטון מטה, על מנת להבין בצורה וויזואלית מה זה DynamoDB, מה הייתרונות ומה השימושים שלו:
יצירת טבלה חדשה #
דרך AWS Console נחפש DynamoDB. נגיע לעמוד בו אנחנו מנהלים את הטבלאות שלנו כחלק מה-DynamoDB. השלב הבא הוא ליצור את טבלת product-inventory.
נלחץ על הכפתור Create table:
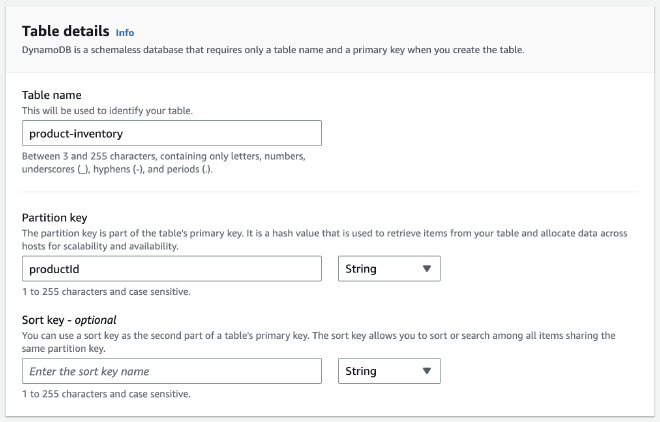
עכשיו נפתח לנו החלון בו נגדיר את הגדרות הבסיס של הטבלה שלנו. שם הטבלה יהיה product-inventory. לאחר מכן נגדיר Partition key שישמש אותנו כתווית הייחודית לכל רשומה בטבלה שלנו (ID), נקרא לו בשם productId מסוג string. לשימוש שלנו אין צורך ב-Sort Key, שמאפשר לשמור את מסד הנתונים מסודר ובכך מייעל את החיפוש על הטבלה.
כמו שציינתי, בשונה ממסדי נתונים מבוססים SQL כאן אין לנו מבנה אחיד לכל הרשומות שלנו. ה-attributes בין כל רשומה יכולים להשתנות, למעט ה-Partition key וה-Sort key.
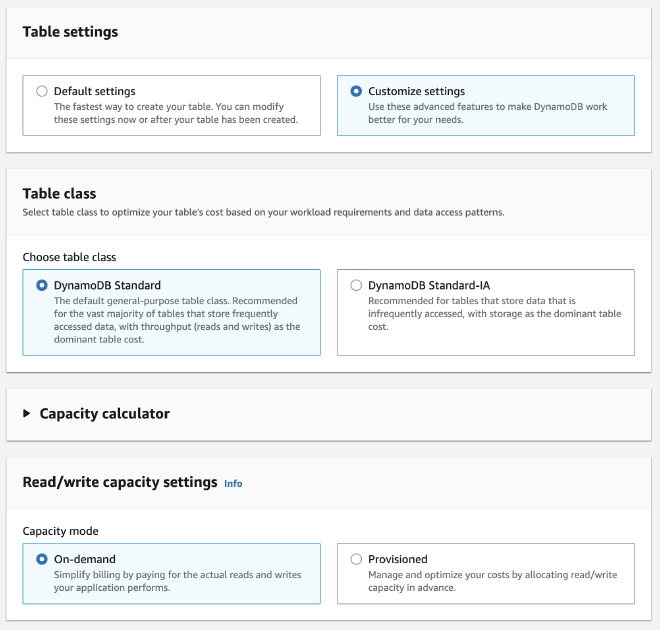
כאשר יוצרים טבלאות חדשות, כבחירת מחדל מוקצה עבורם מקום ייעודי ותשלום מראש. גישה זו מנגדת את הגישת ה-Serverless ולכן נרצה לשנות את הגדרה זו. תחת Table settings נסמן את Custumize settings. חלון חדש ייפתח, בו נסמן תחת Read/write capacity settings את On-demand כך שהמשאבים עבור הטבלה יהיו בהתאם לצורך. לאחר מכן נלחץ על Create table.
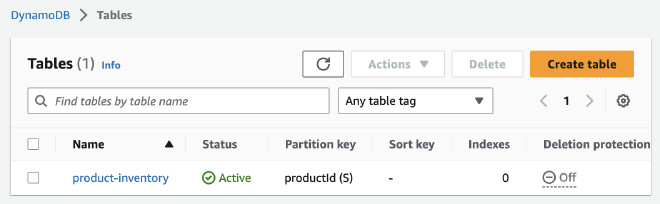
אחרי שפתחנו טבלה בשם product-inventory, הגענו לעמוד הראשי של DynamoDB, בו נוכל לנהל במרוכז את הטבלאות שלנו.
הרשאות 🔑 #
IAM הוא קיצור ל-Identity and Access Management. שירות זה מאפשר ניהול אבטחת המשאבים בענן: מי יכול לגשת ולאיפה, ומה יכולו לעשות בפועל. הרשאות בנויות על פי ההגדרות שלנו לרמת קבוצה של מפתחים ולרמת הפרט. בארגונים גדולים, IAM משמש כלי לריכוז בעלי ההרשאות בצורה מרוכזת.
אחרי שהבנו מטרת שירות זה, נחפש IAM ב-Console, נלחץ מתוך סרגל הכלים מצד שמאל על Roles ולאחר מכן על Create role.
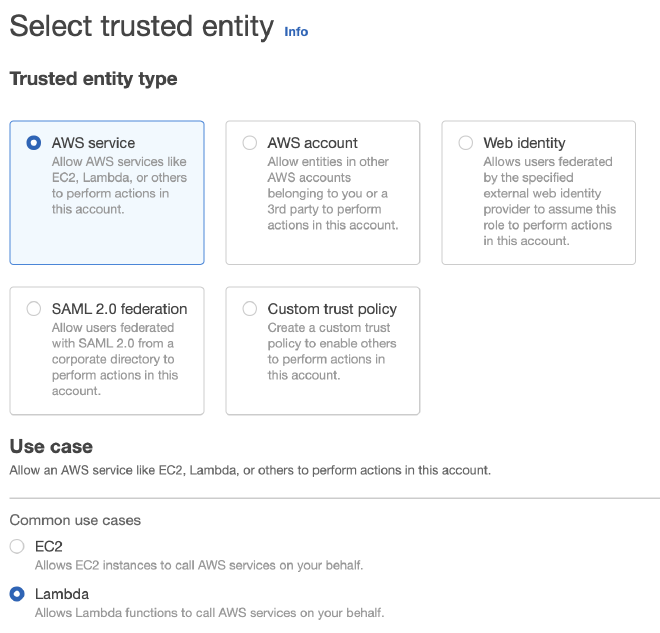
Trust Entity #
השלב הראשון, הוא לבחור מה סוג ההרשאות. נבחר AWS service, וב-Use case נסמן Lambda (בעוד רגע נבין מה זה).
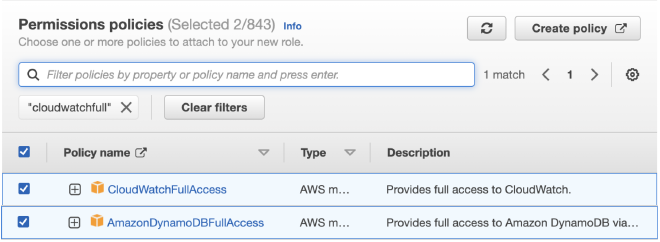
Add Permissions #
AWS עזרו לנו ומציעים Policies מוכנים מראש. Policy זהו פירוט בפועל, אילו פעולות ה-Role מאפשר למשתמש לבצע. נבחר Policies, הראשון CloudWatch, שירות שמרכז את הדפסות ה-Logs כחלק מבקשות ה-API. השני DynamoDB Full Access, שנוכל לבצע פעולות על מסד הנתונים שלנו.
Name, Review and Create #
השלב השלישי והאחרון הוא לקרוא ל-Role בשם, ולוודא שהכל מוגדר כמו שהתכוונו. נקרא ל-Role בשם serverless-api-role, ונלחץ על כפתור Create role.

הגדרת שאילתות 👷♀️ #
לדוגמא, בשביל שנוכל לעדכן רשומה במסד נתונים, נוכל ליצור פונקציה שמקבלת ID של הרשומה אותה נרצה לעדכן ואת הערך החדש. הפונקציה תיגש לרשומה במסד הנתונים, ותעדכן אותה בהתאמה לערך.
על מנת להגדיר פונקציה, דרכה נוכל לעשות פעולות על מסד הנתונים נשתמש בשירות Lambda. נחפש Lambda ב-Console ונלחץ על Create function.
נקרא לפונקציה serverless-api-lambda, נכתוב את הפונקציה נבחר ב-Python. לאחר מכן, תחת כותרת Permissions, נבחר את Role ההרשאות שבנינו serverless-api-role כך נוכל לגשת לטבלה שלנו.
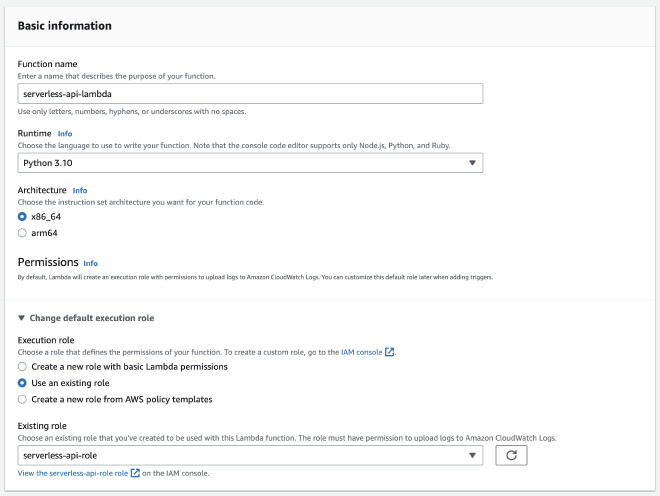
הגענו לעמוד בו בהמשך נכתוב את פונקציית ה-Lambda שלנו. נשאר לנו צעד אחד לפני שנוכל לעשות זאת.
חיבוריות 🤞 #
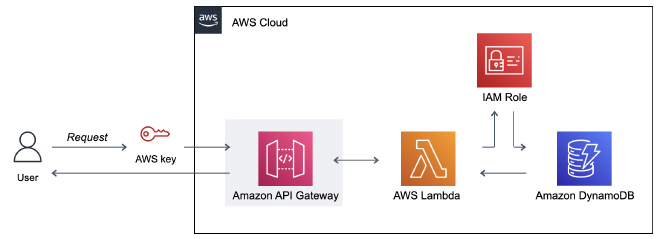
API (קיצור של Application Programming Interface) אוסף של נהלים, פעולות וכלים שמאפשרים תקשורת בין תוכנות ואפליקציות. API Gateway הינו שירות המאפשר בצורה מפוקחת, מאובטח וויזואלית ליצור ולפרסם API, ככה שנוכל לייצר תקשורת בין פונקציות ה-Lambda לבין הטבלה ב-DynamoDB.
ל-API Gateway שלושה יסודות מרכזיים:
- Methods - פעולות HTTP כמו; GET, POST, DELETE וכדומה. לכל Method שינו פונקציית Lambda.
- Resources - מייצג אובייקט במסד הנתונים (כמו משתמשים, מוצרים וכו׳). מסודר על פי סדר היררכי, ויכול להיות עם הזחות על פי הצורך. משמש אותנו כ-Path של הקישור דרכו נבצע שאילתות.
- Endpoints - הקישור דרכו נבצע שאילתות.
לדוגמא, נניח שאנחנו בונים API עבור בלוג. נרצה את השימושים הבאים:
- שליפת כלל הפוסטים:
GET /post - יצירת פוסט חדש:
POST /posts - שליפת פוסט:
GET /posts/{post_id} - עדכון פוסט:
PUT /posts/{post_id} - מחיקת פוסט:
DELETE /posts/{post_id}
איפה היסודות באים לידי ביטוי?
- Recources בא לידי ביטוי ב-
posts/שמייצג אוסף פוסטים וב-posts/{post_id}/שמייצג פוסט מסויים. - Methods בא לידי ביטוי ב-
GET,POST,PUT,DELETE. - Endpoint - יהיה הקישור לשליפה, לדוגמא; https://your-api-id.execute-api.region.amazonaws.com/stage/posts/{post_id}.
בניית API #
אחרי שהבנו מה זה API Gateway ואת יסודותיו, נחפש אותו ב-Console, ונתחיל לבנות REST API.
בחלון זה יהיו הגדרות הבסיס של ה-API החדש שלנו. נבחר New API ולאחר מכן נקרא לו serverless-api.
יצירת Resources #
אחרי שפתחנו API, נגדיר Recources. נלחץ על Action, ולאחר מכן Create Resource.
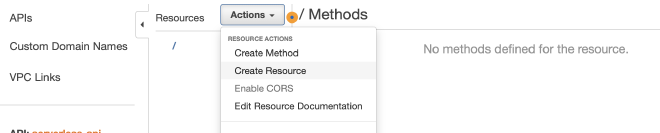
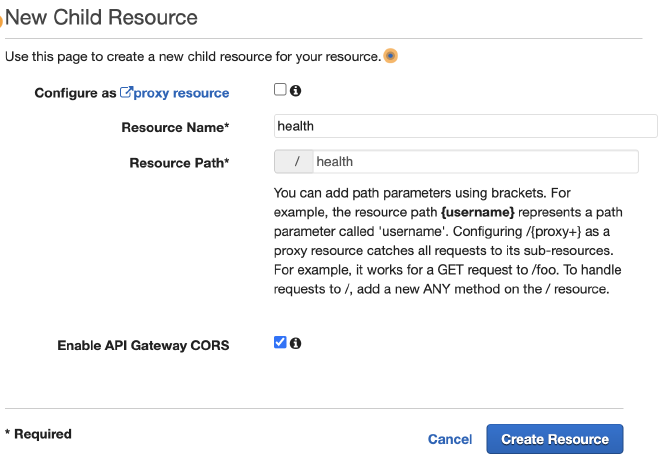
לאחר מכן נכתוב את השם של ה-Resource, ונסמן את Enable API Gateway. נגדיר שלושה Resources שונים; product, health ו-products. נכתוב את השמות, ונסמן את Enable API Gateway CORS.
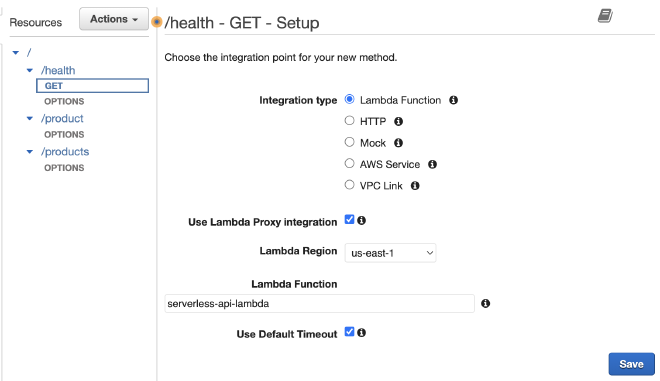
יצירת Methods #
דרך סימון ה-Resource הרלונטי ולחיצה על Actions, נוכל לפתח Methods עבור כל Resource. אילו Methods נפתח ומה יהיה שימושן?

כאשר נגדיר כל פונקציה, נסמן Lambda Proxy וכתבנו את שמה של פונקציית ה-Lambda שלנו.
אחרי שהגדרנו את ה-API והגדרנו אותו, הצעד הבא הוא להפעיל אותו. נלחץ על Action ולאחר מכן Deploy API. נגדיר Stage חדש, ונקרא לו prod. לבסוף נלחץ על Deploy. זהו! עכשיו יש לנו Endpoint, שמופיע תחת Invoke URL.
מפתח גישה #
נחזור ל-API Gateway, ונבחר על אילו Methods נרצה לאבטח עם מפתח ייעודי - API Key. לדוגמא, בחרתי את GET מתוך health/.
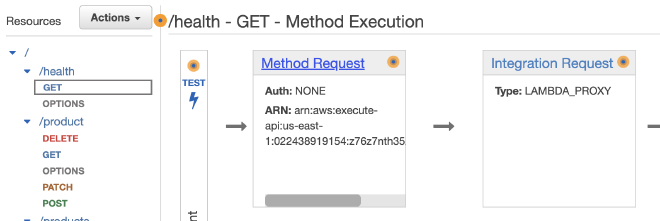
לאחר מכן נלחץ על Method Request, שם נוכל להגדיר שיש חובה לתקשורת דרך API Key. שימו לב שאתם מפרסמים (Deploy) את ה-API אחרי השינויים.
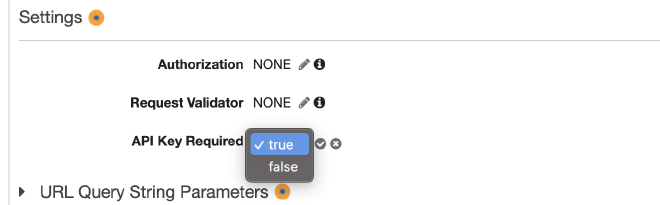
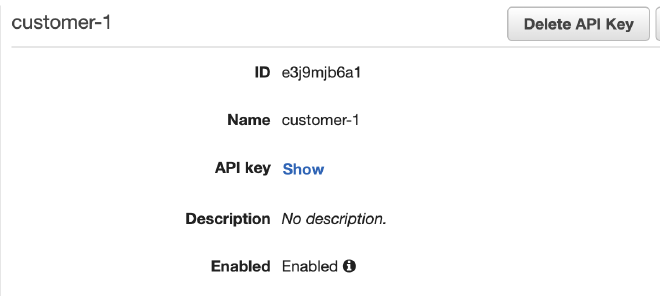
אחרי שהגדרנו את חובה לשאילתות עם API Key, ניצור אחד בעצמנו. תחת API Gateway ניכנס ל-API Keys, וניצור חדש.
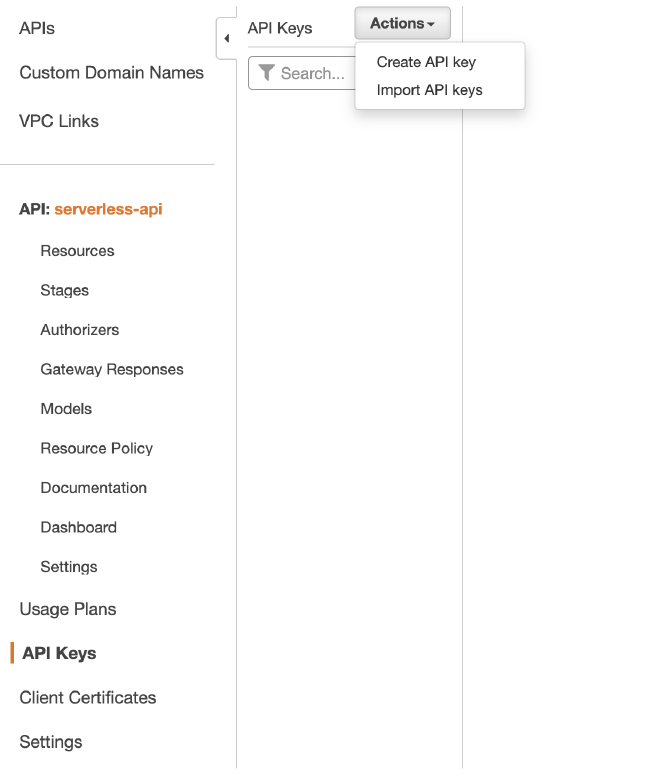
ניתן לו שם customer-1:
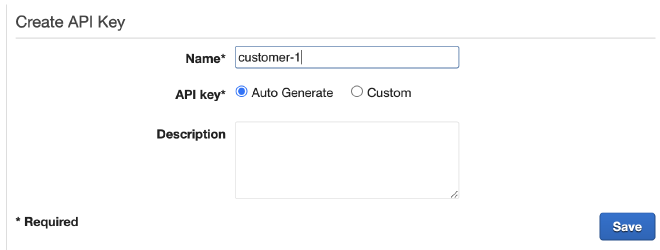
אחרי שנלחץ על Save, נגיע לחלון בו לחשוף את המפתח הסודי שלנו.
תוכנית שימוש #
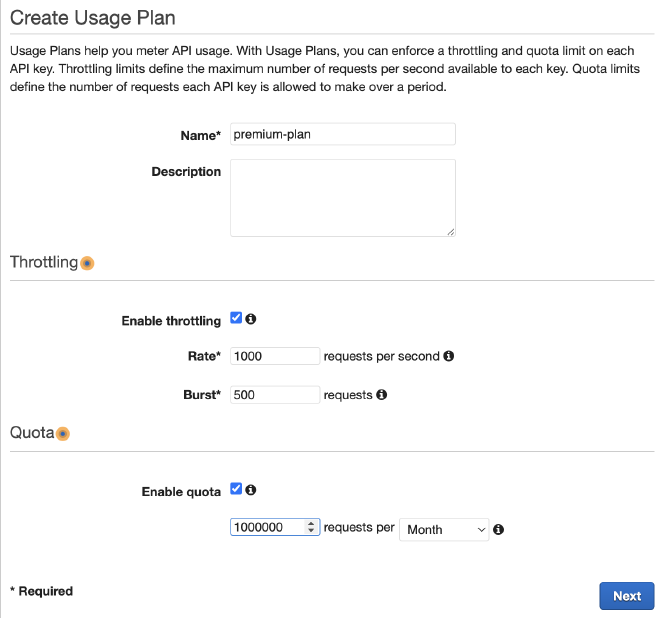
הצעד האחרון הגדרת ה-API יהיה יצירת Usage Plan, שמשמש אותנו לוודא שאין שימוש יתר ב-API שלנו מעבר לתכנון. תחת API Gateway ניכנס ל-Usage Plan, וניצור חדש.

נקרא לתוכנית שימוש בשם premium-plan, ונגדיר את קצבי השימוש:
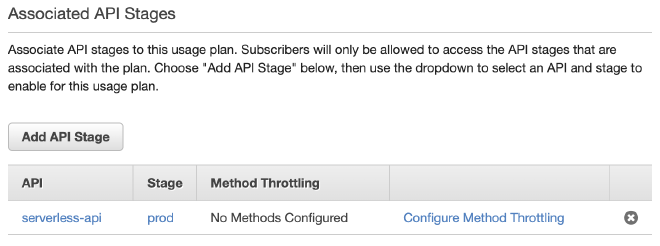
לאחר מכן נחבר את התוכנית ל-API שלנו:
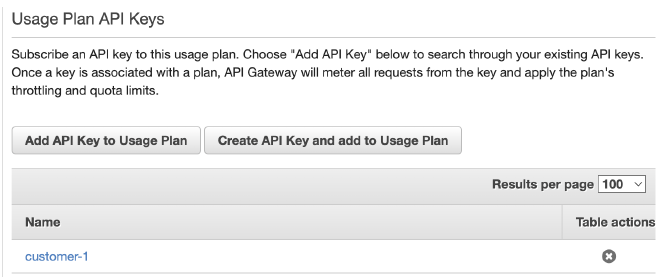
נלחץ על כפתור Add API Key ונחבר בין ה-Usage plan ל-API Key. לאחר מכן נלחץ Done:
מימוש שאילתות 😱 #
עכשיו שסביבת הענן שלנו מוכנה, הכל מחובר ומאובטח נוכל לתכנת את הפונקציית Lambda שלנו. אישית אני מעדיף לעבוד ב-IDE ולא על ה-Console, אבל זה השיקול שלכם. לפני שנתחיל נחשוב, איך נפעיל פונקציית Lambda? דרך טריגר (trigger). קיימים סוגים שונים של טריגרים, ואצלנו הוא ה-API Gateway שבנינו.
Local Variables #
לפני הכל נציין הפניה לספריות בהן נשתמש, שהם boto3, JSON ו-logging.
import boto3 # AWS SDK for Python
import json # response handling
import logging # log handling
לאחר מכן, נגדיר אובייקט Log שיעזור לנו לתעד ולשמור הודעות log.
logger = logging.getLogger()
logger.setLevel(logging.INFO)
בשלב הבא, נגדיר משתנה בו יהיה שם הטבלה שלנו, נגדיר עוד משתנה שיכיל הפניה לשירות DynamoDB כמשתנה. נקרא לטבלה שלנו דרך שמה:
dynamodbTableName = 'product-inventory'
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table(dynamodbTableName)
נגדיר את המשתנים הקבועים באמצעותם נוכל לדעת מה סוג הקריאה של ה-API. הם מחולקים ל- Methods ול-Resource, בהתאם למבנה של API שהגדרנו בפרק ״חיבוריות״:
getMethod = 'GET'
postMethod = 'POST'
patchMethod = 'PATCH'
deleteMethod = 'DELETE'
healthPath = '/health'
productPath = '/product'
productsPath = '/products'
event ו-context #
כאשר Lambda מופעלת (invoked), הפונקציה lambda_handler נקראת ובעצם מהוות שער הכניסה לפונקציה.
def lambda_handler(event, context):
event- פרטי הטריגר שהפעיל את הפונקציה. ב-API Gateway, מכיל את הפרטים אודות בקשת ה-HTTP:httpMethod- פונקציית ה-HTTP שה-API השתמש, לדוגמא:GET,POST,PATCH,DELETEוכדומה.path- ה-API endpoint דרכה התבצעה בקשת ה-HTTP.headers- ה-headers שנשלחו כחלק מהבקשה.queryStringParameters- הפרמטרים שנשלחו כחלק מה-URL בבקשה.body- התוכן שקיבלנו מהבקשה. רלוונטי בעיקר בבקשותPOSTאוPUT.
context- פרטי סביבת זמן הריצה:awsRequestId- ערך חד-חד-ערכי שמייצג את הריצה הנוכחית של פונקציית ה-Lambda.functionName- שם הפונקציה שהופעלה.memoryLimitInMB- כמות הזיכרון אשר מוקצה לפונקציה.logGroupName- ה-Amazon CloudWatch log group אשר משוייך לפונקציה.logStreamName- ה-Amazon CloudWatch log stream אשר משוייך לפונקציה.getRemainingTimeInMillis- הזמן שנשאר לפונקציה לרוץ עד שיהיה time out.
Response Handling #
אחרי שהבנו את הארגומנטים, הצעד הבא שלנו הוא להבדיל בין ה-Methods אותם נצטרך להריץ, ועל אילו Recourses.
נדפיס את האורגומנט event ב-log שיעזור לנו בתהליכי debug, ונשמור במשתנים נפרדים את ה-HTTP Method וה-Path. (Path הוא ה-Resource):
def lambda_handler(event, context):
logger.info(event)
httpMethod = event['httpMethod']
path = event['path']
בעזרת המשתנים הקבועים שהגדרנו, נוכל להבדיל בין כל סיבת קריאה, ולקרוא לפונקציות Python בהתאם לסוג בקשת ה-HTTP. לפני שאפרט על כל פונקציה, ניצור פונקציה שתבנה לנו את ה-JSON שנחזיר ב-Response, פונקציית buildResponse:
def buildResponse(statusCode, body=None):
response = {
'statusCode': statusCode,
'headers': {
'Context-Type': 'application/json',
'Access-Control-Allow-Origin': '*'
}
}
if body is not None:
# objects from dynamodb in decomals, create CustomEncoder
response['body'] = json.dumps(body, cls=CustomEncoder)
return response
response- התגובה של הפונקציה שלנו, בפורמט JSON:statusCodeמייצג את סטטוס הפונקציה, לדוגמא 404, 500, 200 וכו׳.headersמייצגים את הפורמט של ה-response. בנוסף, מוגדר גישה ל-API מכל מקום באמצעותAccess-Control-Allow-Origin.
CustomEncoder- מקודד JSON מותאם אישית:- בטבלאות DynamoDB המשתנים נשמרים לרמת Decimal. רמת רזולוציה כזו (96-bit) עוזרת לדיוק גבוה יותר וייצוג טווח ערכים רחב יותר בהשוואה ל-Float. כיום JSON אינו תומך בכך, ונצטרך להמיר את האובייקטים לייצוג שפורמט JSON תומך כך שלא יהיו תקלות בתגובה.
- נבנה מקודד מותאם אישית
CustomEncoderשימיר את המשתנים מסוג Decimal ל-Float. - נשמור את המקודד בקובץ Python ייעודי, ונקרא לו
custom_encoder.py. חשוב להוסיף הפניה לקובץ זה בקובץ הראשי שלנו, על מנת שנוכל לעשות שימוש במקודד:from custom_encoder import CustomEncoder - נקרא למקודד בעזרת
json.dumps. - אז, איך פונקציית
CustomEncoderנראת?
import json
from decimal import Decimal
class CustomEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, Decimal):
return float(obj)
return json.JSONEncoder.default(self, obj)
Python Functions #
הגענו ללב פונקציית ה-Lambda שלנו, החלק בו נבדוק את ה-Methods וה-Resources ונקרא לפונקציות. דרך הגרף מטה נוכל להבין בצורה ויזואלית אילו פונקציות נבנה ובאילו תנאים נקרא להן. אזכיר ששמרנו כמשתנה גלובלי table הפניה לטבלה שלנו, במשתנה זה נעשה שימוש לאורך כל הפונקציות.
def lambda_handler(event, contextdef lambda_handler(event, context):
...
if httpMethod == getMethod and path == healthPath:
# 1 - GET Health
elif httpMethod == getMethod and path == productPath:
# 2 - GET Product
elif httpMethod == getMethod and path == productsPath:
# 3 - GET Products
elif httpMethod == postMethod and path == productPath:
# 4 - POST Product
elif httpMethod == patchMethod and path == productPath:
# 5 - PATCH Product
elif httpMethod == deleteMethod and path == productPath:
# 6 - DELETE Product
else:
# 7 - ERROR
GET Health- תשובה אודות סטטוס פעילות ה-API. לא ניצור עבור כך פונקציה ייעודית, אלא נחזיר תשובה 200, שאומרת תקין.
response = buildResponse(200)
GET Product- פונקציה המקבלת ID של מוצר, ומחזירה את הרשומה שלו בטבלה.
response = getProduct(event['queryStringParameters']['productId'])
⬇
def getProduct(productId):
try:
response = table.get_item(Key={'productId': productId})
if 'Item' in response:
return buildResponse(200, response['Item'])
else:
return buildResponse(404, {'message': 'Product not found'})
except Exception as e:
logger.error(e)
return buildResponse(500, {'message': 'Error getting product'})
- בקראיה לפונקציה, באמצעות
queryStringParametersנוכל לדעת מה ה-ID של המוצר עליו התבקשנו להביא את פרטיו. - נשתמש בפונקצייה המובנת
get_itemשתחזיר לנו את הרשומה של המוצר. - במידה ואנחנו מוצאים את המוצר, נחזיר אותו. במידה ולא, נחזיר הודעות שגיאה.
GET Products- פונקציה שמחזירה את כלל הרשומות של המוצרים שיש לנו בטבלה.
response = getProducts()
⬇
def getProducts():
try:
items = []
last_evaluated_key = None
response = {'LastEvaluatedKey': True}
while last_evaluated_key is None or 'LastEvaluatedKey' in response:
if last_evaluated_key:
response = table.scan(ExclusiveStartKey=last_evaluated_key)
else:
response = table.scan()
if 'Items' in response:
items.extend(response['Items'])
last_evaluated_key = response.get('LastEvaluatedKey')
if items:
return buildResponse(200, items)
else:
return buildResponse(404, {'message': 'No products found'})
except Exception as e:
logger.error(e)
return buildResponse(500, {'message': 'Error getting products'})
- נקפוץ לתוכן הלולאה. בעזרת
table.scanנקרא את טבלה, ואת התוצאה נשמור במשתנהresponse. משתנה זה מכיל 2 סוגים של מידע בהם נעשה שימוש:Itemsמידע הרשומות ששלפנו, ו-LastEvaluatedKeyשמצביע על החלק הבא בטבלה - מה זה אומר? - מסדי נתונים יכולים להיות מאוד גדולים. לעיתים לא נרצה לשלוף את כל הטבלה, אלא רק חלק ממנה. לדוגמא, שאנחנו גולשים ברשת חברתית, האפליקציה לא טוענת את כל הפוסטים, אלא רק מה שקרוב לטווח הראייה שלנו. עקרון זה נקרא Paging, והוא קיים גם ב-DynamoDB בשם Pagination Feature. כך נוכל להציב רף של כמות המידע שנוכל לשלוף בפעם אחת (1 MB כבחירת מחדל).
- במשתנה
itemsנרכז את נתוני הרשומות את הנתונים דרך ה-responseבעזרת פונקצייתextend, ונעדכן את משתנהlast_evaluated_keyבהתאם לתוצאת הריצה. - בלולאה נבדוק אם
LastEvaluatedKeyהואNone. אם לא, נמשיך לשלוף. אם כן, סיימנו לשלוף את הנתונים על הטבלה ואפשר להחזיר את תוצאות השליפה.
POST Product- פונקציה ששומרת את הרשומה על פי JSON שהיא מקבלת.
response = saveProduct(json.loads(event['body']))
⬇
def saveProduct(productBody):
try:
table.put_item(Item=productBody)
return buildResponse(201, {'message': 'Product saved'})
except Exception as e:
logger.error(e)
return buildResponse(500, {'message': 'Error saving product'})
- נצא להנחה שהפונקציה מקבלת כחלק מה-JSON את כל הפרטים הנחוצים לשמירת המוצר. הנתון החשוב הוא ה-
productId, שהמשתמש מגדיר. מי שרוצה להפוך את הפונקציה ליותר גנרית, מציע לעבוד עם UUID. - ניקח את
productBodyונשמור אותו בעזרתput_item. במידה ותהיה תקלה בזמן השמירה, נציג אותה.
PATCH Product- פונקציה זו מעדכנת נתוני Product קיים בטבלה.
requestBody = json.loads(event['body'])
response = modifyProduct(requestBody['productId'], requestBody['updateKey'], requestBody['updateValue'])
⬇
def modifyProduct(productId, updateKey, updateValue):
try:
response = table.update_item(
Key={'productId': productId},
UpdateExpression=f'SET {updateKey} = :val',
ExpressionAttributeValues={':val': updateValue},
ReturnValues='UPDATED_NEW'
)
if 'Attributes' in response:
return buildResponse(200, response['Attributes'])
else:
return buildResponse(404, {'message': 'Product not found'})
except Exception as e:
logger.error(e)
return buildResponse(500, {'message': 'Error updating product'})
- לפני הפונקציה
modifyProduct, הוצאנו את פרטי המוצר שנרצה לעדכן דרך ה-bodyמה-event. הפרטים הם: מזהה המוצרproductId, שם העמודה שנרצה לעדכןupdateKeyוהערך החדשupdateValue. - כמו שאתם רואים, הוצאנו מראש את פרטי המוצר ולא עשינו את זה כחלק מהפונקציה. הסיבה היא שמירת קוד נקי, מוכן לשימוש חוזר. גישה זו תקל עלינו בתחזוקה.
- בתוך
try, נשתמש ב-update_itemעל אובייקטtableעל מנת לשמור את השינויים:key- מגדיר את ה-ID של הרשומה שנרצה לשמור, במקרה שלנוproductId.UpdateExpressionו-ExpressionAttributeValues- באמצעותם נגדיר באיזו צורה נשנה ערכי נתונים ואילו נתונים. חלק מהפעולות שאפשר לעשות הן להגדיר ערך חדש, הוספת מספר, הסרת עמודה ועוד.ReturnValues- מחרוזת המגדירה איזה מידע צריך לחזור אחרי פעולת העדכון. במקרה שלנו, כתבנו את הצהרתUPDATED_NEWשאומרת שהיא תחזיר את הערך העדכני.
- המשך הפונקציה היא בדיקות לתקינות העדכון, ועדכון המשתמש בהתאמה.
DELETE Product- פונקציה אשר מוחקת מוצר על פי ID.
requestBody = json.loads(event['body'])
response = deleteProduct(requestBody['productId'])
⬇
def deleteProduct(productId):
try:
response = table.delete_item(Key={'productId': productId})
if response['ResponseMetadata']['HTTPStatusCode'] == 200:
return buildResponse(200, {'message': 'Product deleted'})
else:
return buildResponse(404, {'message': 'Product not found'})
except Exception as e:
logger.error(e)
return buildResponse(500, {'message': 'Error deleting product'})
- נוציא את ה-ID של המוצר שנרצה למחוק דרך ה-
bodyמה-event. - נשתמש בפונקצייה
delete_itemמתוך אובייקטtableשמקבל את ה-ID של המוצר, ומחזיר תשובת סטטוס בהתאמה בעזרתResponseMetadata. - על פי התשובה נחזיר הודעה למשתמש.
ERROR- אם הגענו לפה, זה אומר שהייתה שגיעה בצורת הבקשה, המשתמש ביקש משהו שלא נתמך ב-API, ולכן נחזיר 404.
response = buildResponse(404, 'Not Found')
את lambda_handler יחד עם כלל הפונקציות שבנינו נדביק בפונקציית ה-Lambda שלנו. נזכור לפתוח קובץ לו נקרא custom_encoder.py ונשמור בו את המקודד שבנינו בהתחלה. אחרי כל השינויים נעשה Deploy לפונקציה.
Postman ⚡️ #
ביישורת האחרונה שלנו, נשאר לנו לבדוק את ה-API שבנינו. דרך ה-Console ניגש ל-API Gateway, נעתיק את ה-Endpoint ונדביק אותו ל-URL ב-Postman.
לדוגמא, אני רוצה לבצע הכנסה של מוצר חדש למסד הנתונים. בואו נבנה יחד את בקשת ה-HTTP:
- נדביק את ה-Endpoint, אחריו אוסיף
product/,וניצור URL, לדוגמא: https://{endpoint}/product. - משמאל ל-URL, נסמן את Method ה-POST.
- נוסיף את המפתח שלנו ל-API ב-Headers. ה-Key יהיה
x-api-keyוה-Value יהיה המחרוזת שמייצגת את המפתח. - ב-Body של הבקשה נסמן את אופציית raw ו-JSON. לאחר מכן נכתוב את תוכן הבקשה, כך שיכיל את ה-ID של המוצר החדש ואת מאפייניו:
{
"productId": "131",
"color": "red",
"price": 1323
}
- נקבל בחזרה הודעה שהכל עודכן כמו שצריך:
{
"message": "Product saved"
}
וזהו סיימנו! 🥳 אשמח לשמוע מכם מה בניתם באמצעות המדריך שלי. בהצלחה!